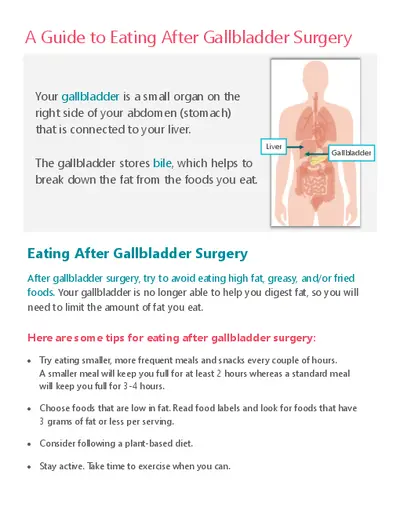
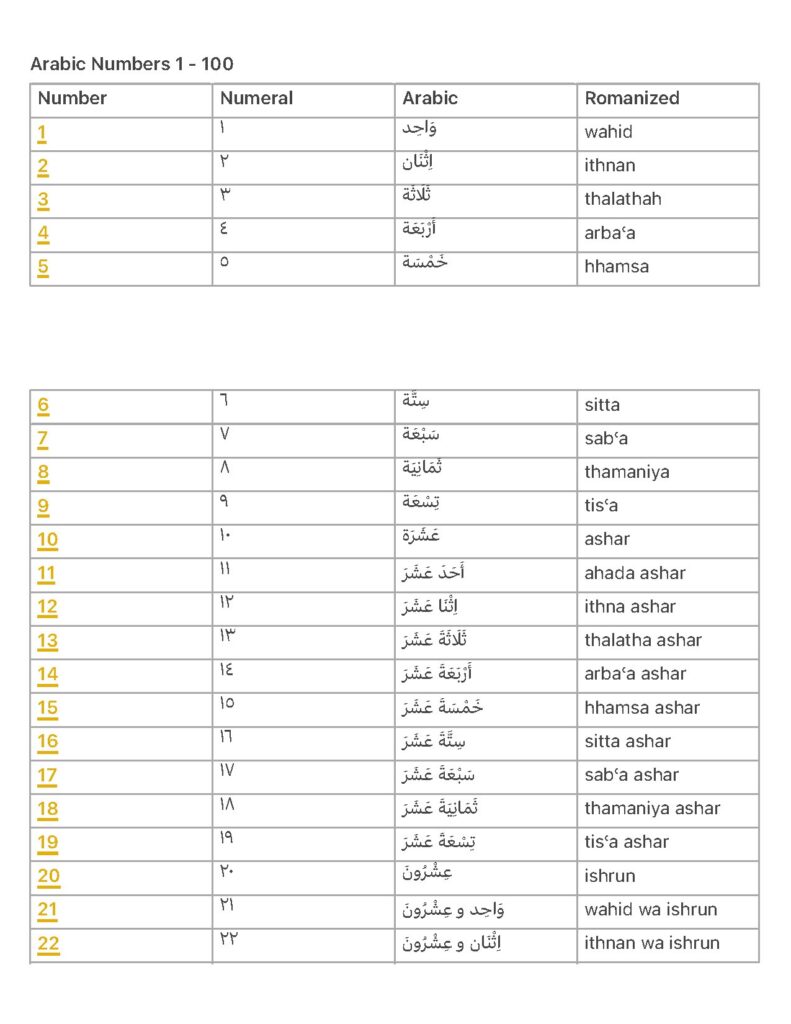
The data science model-building life cycle outlines essential steps for solving business problems through data analysis and prediction. Key phases include problem definition, hypothesis generation, data collection, exploration, predictive modeling, and model deployment. This framework is crucial for data analysts and business professionals aiming to derive insights from data effectively. It emphasizes the importance of understanding the problem context and choosing appropriate analytical methods. The guide serves as a comprehensive resource for those involved in data-driven decision-making processes.
Key Points
- Explains the data science model-building life cycle for analytics.
- Covers essential steps including problem definition and data collection.
- Details predictive modeling techniques and model deployment strategies.
- Discusses the importance of hypothesis generation and data exploration.