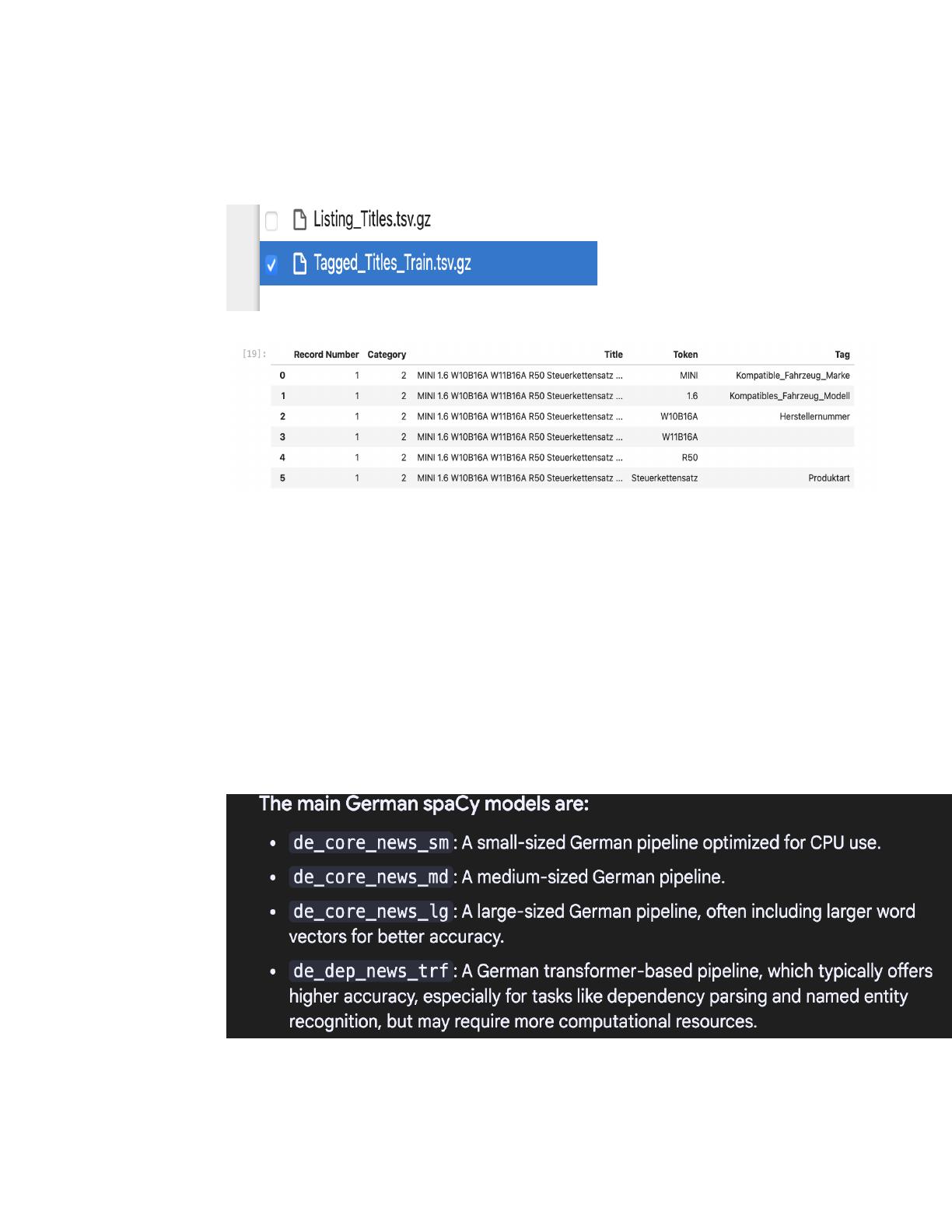
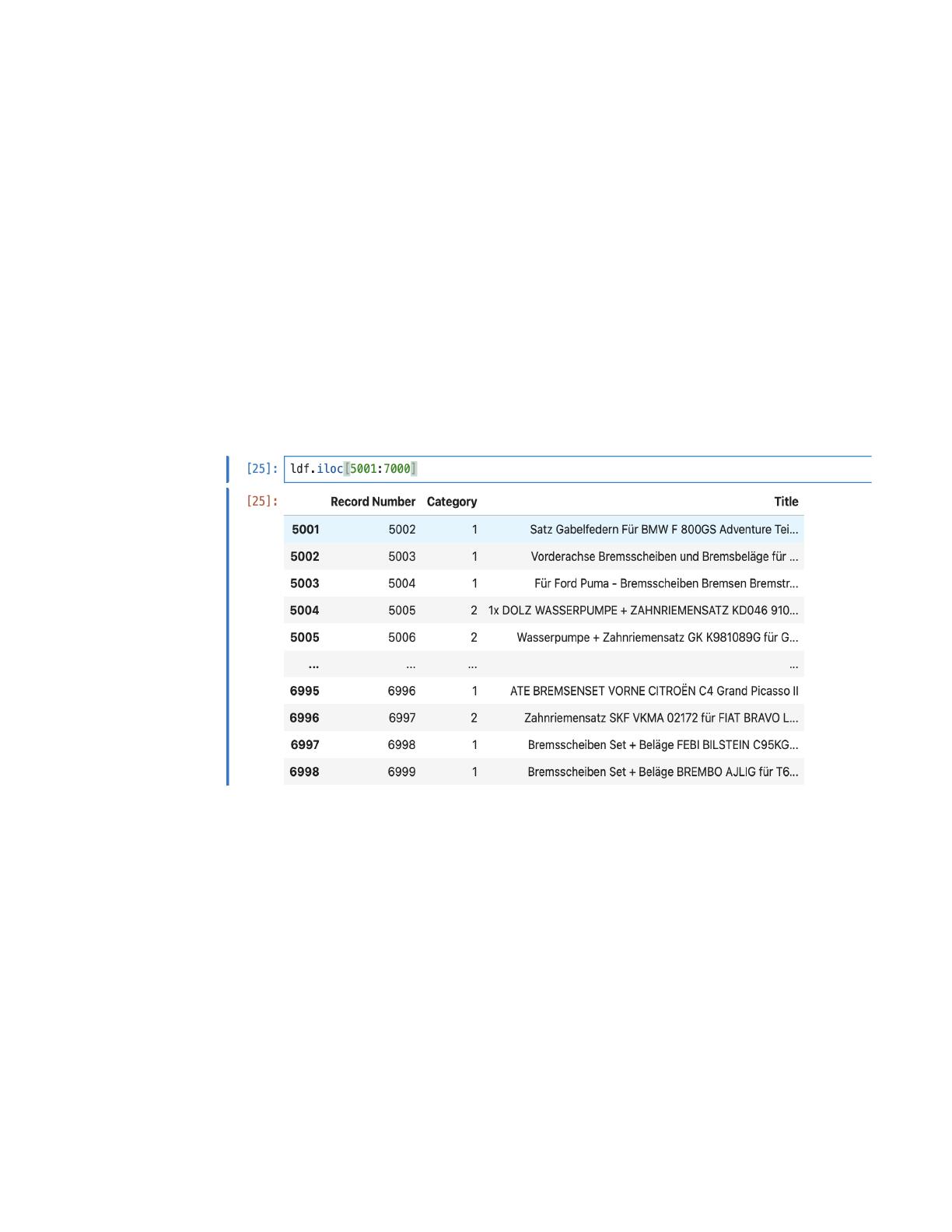
The eBay Machine Learning Hackathon dataset analysis focuses on two primary datasets, including 2 million testing records and 5,000 training records. It outlines the process of combining multi-token entities for Named Entity Recognition (NER) tasks, specifically targeting aspects like product names and manufacturers. The analysis emphasizes the importance of preparing data for fine-tuning German language models with Spacy. This resource is essential for data scientists and machine learning practitioners interested in e-commerce applications and NER methodologies.
Key Points
- Analyzes two datasets for eBay's machine learning hackathon, including 2M testing records and 5K training records.
- Explains the process of combining multi-token entities for effective Named Entity Recognition (NER).
- Details the use of Spacy's German models for fine-tuning on specific categories like product and manufacturer.
- Provides insights into preparing data for machine learning applications in e-commerce.