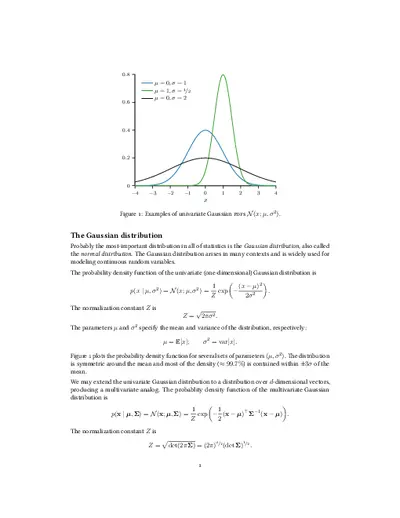
Univariate Gaussian distributions are fundamental in statistics, illustrating how continuous random variables behave. The document provides visual examples of probability density functions (PDFs) for various mean and variance parameters, showcasing the symmetric nature of the Gaussian curve. It serves as an essential resource for students and professionals studying statistical methods and probability theory. The content includes mathematical formulations and graphical representations, making it suitable for those preparing for exams in statistics or data analysis.
Key Points
Illustrates univariate Gaussian probability density functions with different parameters.
Explains the significance of mean and variance in Gaussian distributions.
Includes visual representations to aid understanding of statistical concepts.
Serves as a resource for students studying statistics and probability theory.
This link leads to an external site. We do not know or endorse its content, and are not responsible for its safety. Click the link to proceed only if you trust this site.
What are the key characteristics of univariate Gaussian distributions?
Univariate Gaussian distributions are defined by their mean (µ) and variance (σ²), which determine the shape and spread of the distribution. The probability density function (PDF) is symmetric around the mean, with approximately 99.7% of the data falling within three standard deviations from the mean. This property makes the Gaussian distribution crucial for statistical analysis, as it often describes the behavior of real-valued random variables in various fields.
How does the variance affect the shape of a Gaussian distribution?
Variance in a Gaussian distribution determines the width of the curve. A smaller variance results in a steeper curve, indicating that the data points are closely clustered around the mean. Conversely, a larger variance produces a flatter curve, suggesting that the data points are more spread out. Understanding this relationship is essential for interpreting statistical data and making predictions based on Gaussian models.
What is the significance of the normalization constant in Gaussian distributions?
The normalization constant in Gaussian distributions ensures that the total area under the probability density function equals one, making it a valid probability distribution. For univariate Gaussian distributions, this constant is derived from the variance and is crucial for accurately calculating probabilities. Without this normalization, the distribution would not properly represent the likelihood of different outcomes.
What applications do univariate Gaussian distributions have in statistics?
Univariate Gaussian distributions are widely used in various statistical applications, including hypothesis testing, confidence intervals, and regression analysis. They serve as the foundation for many statistical methods, allowing researchers to model and analyze data effectively. Additionally, they are used in machine learning algorithms, where assumptions of normality can simplify complex calculations and improve model performance.
Related of Figure 1: Examples of univariate Gaussian