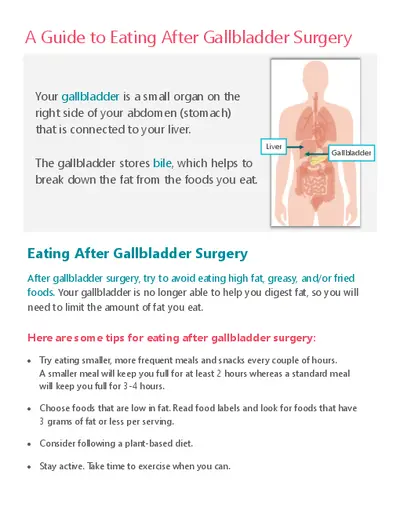
Forecasting Characteristic 3D Poses of Human Actions
Forecasting characteristic 3D poses focuses on predicting future human actions based on short sequences of observed poses. The research, authored by Christian Diller, Thomas Funkhouser, and Angela Dai, introduces a probabilistic approach to model multi-modal distributions of likely future poses. This work is essential for applications in robotics, human-robot interaction, and video generation. The study evaluates a new dataset of annotated characteristic poses, demonstrating significant improvements over traditional time-based forecasting methods. Ideal for researchers and practitioners in computer vision and machine learning, this paper provides insights into human motion prediction methodologies.
Key Points
Introduces a probabilistic approach for forecasting characteristic 3D poses in human actions.
Evaluates a new dataset of annotated characteristic poses for improved human motion prediction.
Demonstrates significant performance improvements over traditional time-based forecasting methods.
Applicable for robotics, human-robot interaction, and video generation tasks.
This link leads to an external site. We do not know or endorse its content, and are not responsible for its safety. Click the link to proceed only if you trust this site.
FAQs of Forecasting Characteristic 3D Poses of Human Actions
What is the main objective of forecasting characteristic 3D poses?
The main objective of forecasting characteristic 3D poses is to predict future human actions by analyzing short sequences of observed poses. This approach focuses on identifying key moments that define the intent of actions, such as reaching for an object or preparing to drink. By decoupling temporal aspects from intentional behavior, the research aims to enhance the understanding of human actions in various applications, including robotics and surveillance.
How does the proposed method improve upon traditional forecasting techniques?
The proposed method improves upon traditional forecasting techniques by utilizing a probabilistic framework that captures the multi-modal distribution of likely future poses. Unlike conventional time-based methods that predict poses at fixed intervals, this approach focuses on predicting semantically meaningful characteristic poses that align with the goals of human actions. This results in more accurate and diverse predictions, allowing for better anticipation of human behavior.
What datasets were used to evaluate the forecasting method?
The forecasting method was evaluated using a new dataset constructed from the GRAB and Human3.6M datasets. These datasets include a variety of human actions captured through motion capture technology, providing a comprehensive set of annotated characteristic poses. The evaluation demonstrates the effectiveness of the proposed method in accurately predicting future poses based on observed sequences.
What applications can benefit from the findings of this research?
The findings of this research can benefit various applications, including robotics, where understanding human actions is crucial for effective human-robot interaction. Additionally, the method can be applied in surveillance systems to predict and analyze human behavior in real-time. Other potential applications include video generation and animation, where accurate pose forecasting enhances the realism of character movements.
Related of Forecasting Characteristic 3D Poses of Human Actions